|
YouTube users looking for instructions for a specific task may spend a long time browsing content
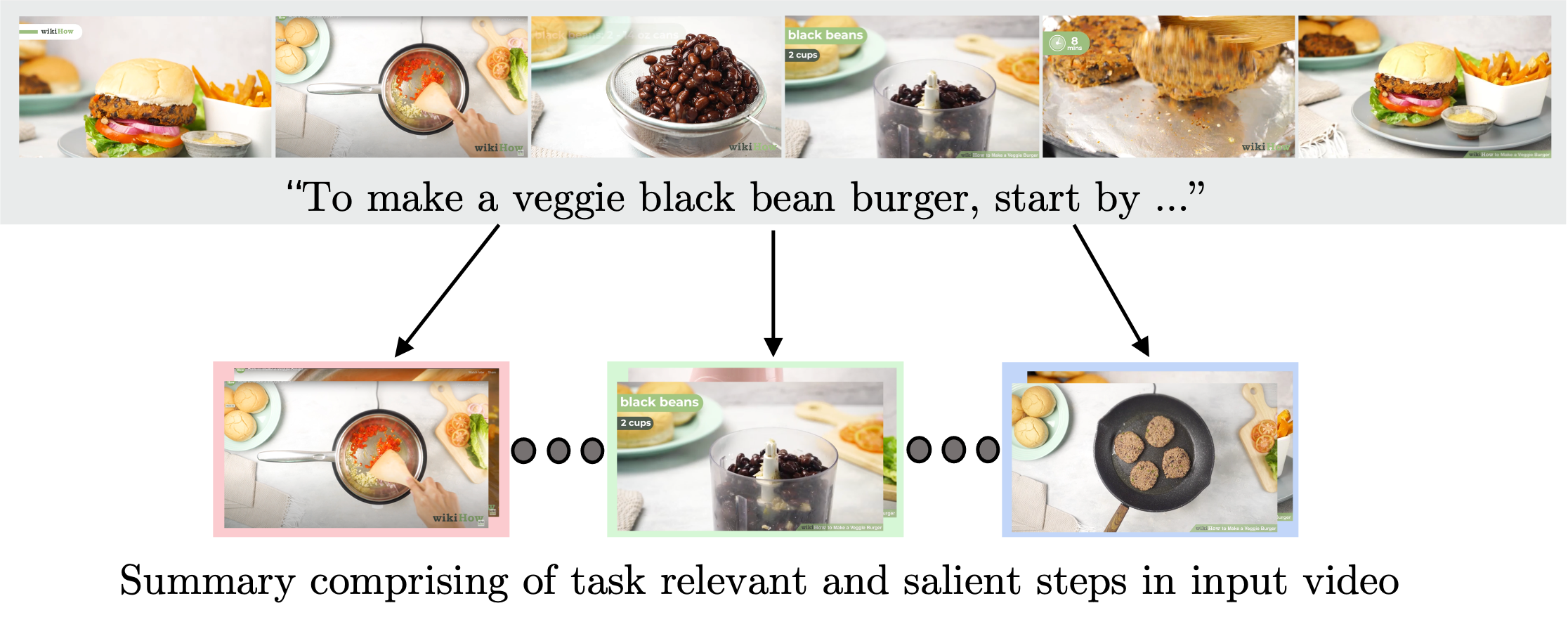
trying to find the right video that matches their needs. Creating a visual summary (abridged version
of a video) provides viewers with a quick overview and massively reduces search time. In this work,
we focus on summarizing instructional videos, an under-explored area of video summarization.
In comparison to generic videos, instructional videos can be parsed into semantically meaningful
segments that correspond to important steps of the demonstrated task. Existing video summarization
datasets rely on manual frame-level annotations, making them subjective and limited in size. To
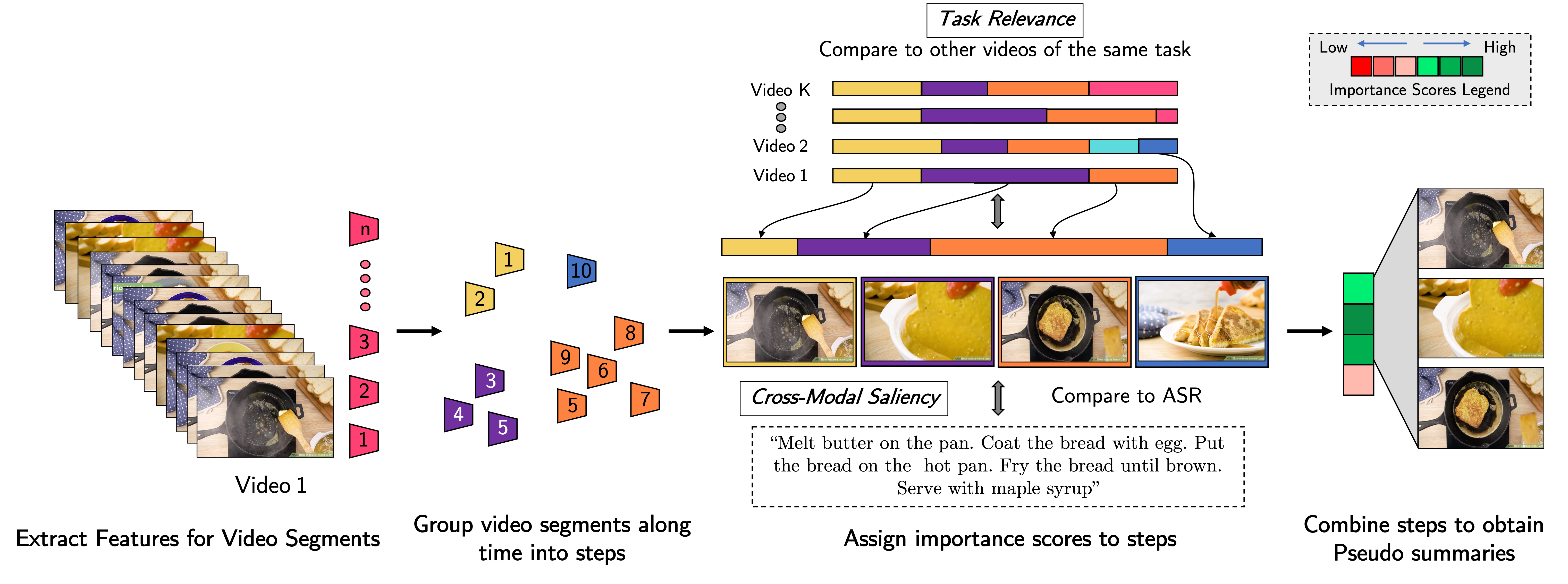
overcome this, we first automatically generate pseudo summaries for a corpus of instructional
videos by exploiting two key assumptions: (i) relevant steps are likely to appear in multiple videos
of the same task (Task Relevance), and (ii) they are more likely to be described by the
demonstrator verbally (Cross-Modal Saliency). We propose an instructional video summarization
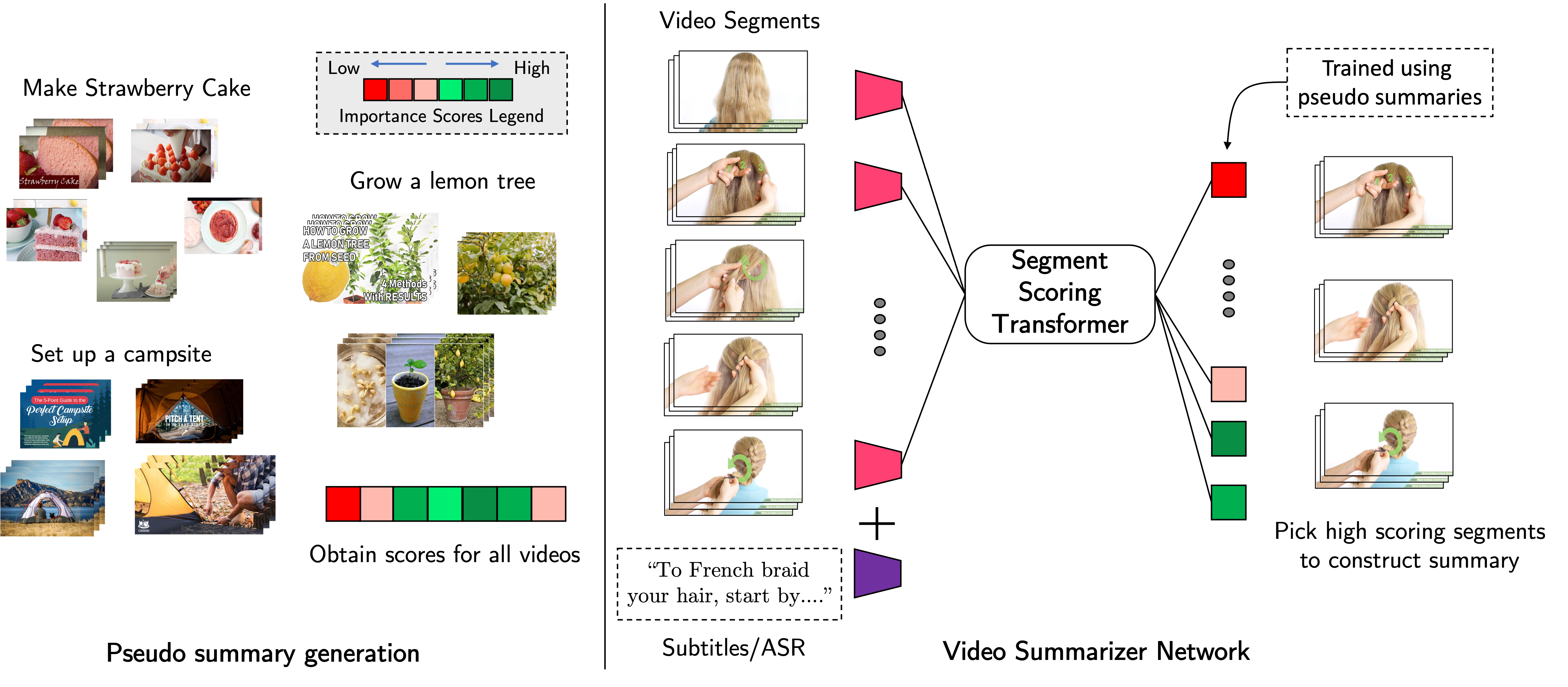
network that combines a context-aware temporal video encoder and a segment scoring transformer.
Using pseudo summaries as weak supervision, our network constructs a visual summary for an
instructional video given only video and transcribed speech. To evaluate our model, we collect a
high-quality test set, WikiHow Summaries, by scraping WikiHow articles that contain video
demonstrations and visual depictions of steps allowing us to obtain the ground-truth summaries. We
outperform several baselines and a state-of-the-art video summarization model on this new benchmark.
|